Chapter 4 Theory
We already introduced egonets in section 1.4.1. We defined an egonet as the set of ties surrounding sampled individual units. (cf. Marsden 1990). Thus we have an ego with ties to one or more alters. Suppose that after we have identified the alters of ego, we asked ego the following follow-up question:
How close are these people to each other?
1.very close
2.not close, but not total strangers to each other either
3.total strangers to each other
4.I don’t know
In this situation we also have information on ties between ego’s alters and, subsequently, we may observe triads between our alters. In the figure below I have made the triad green.
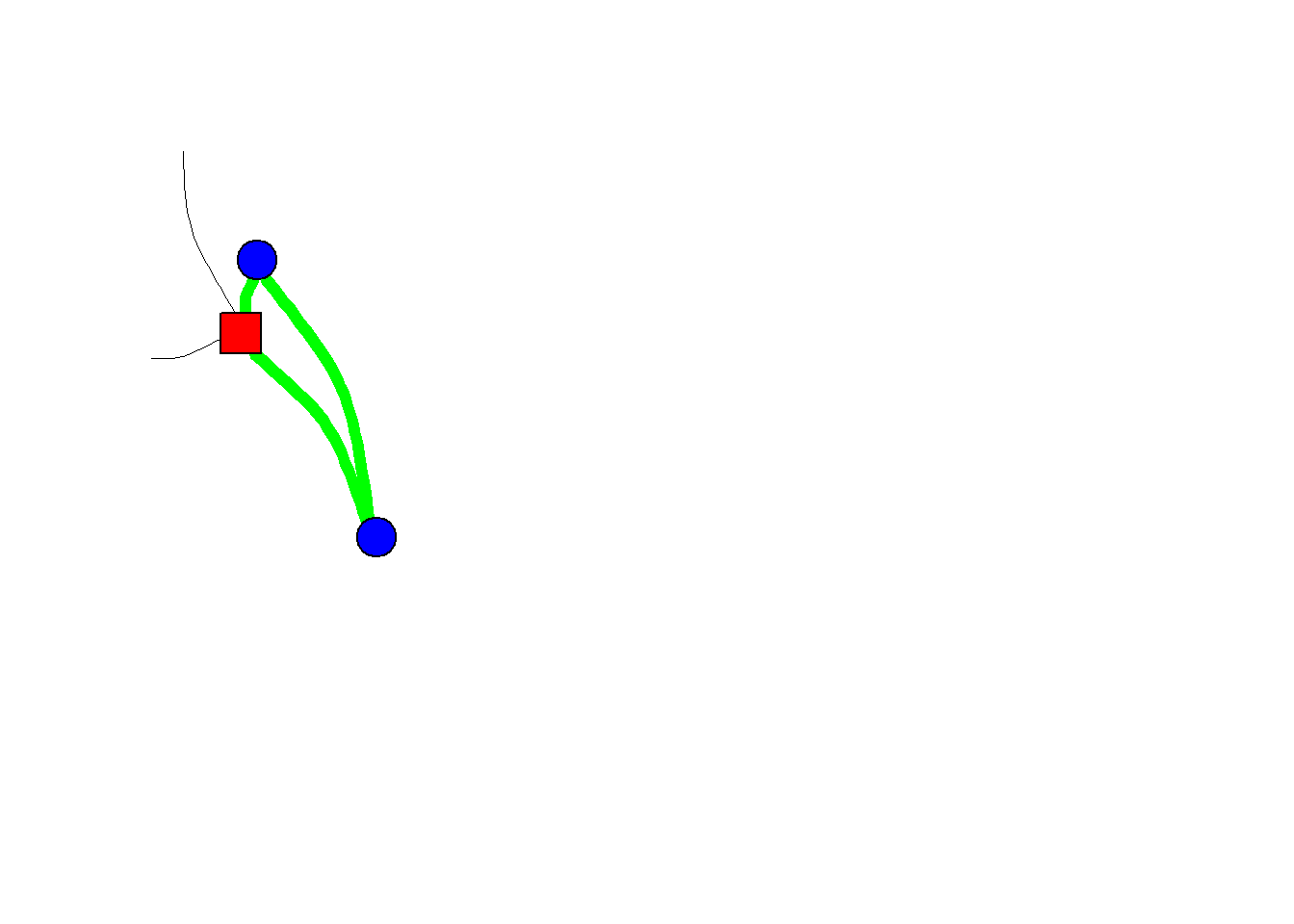
Figure 4.1: A Triad within an egonet
Let us discuss TRIADS in some more detail first, before we move on with our discussion on Egonets.
4.1 Network Structures (TRIAD)
Let us start with all possible triad configurations if we have a (binary) undirected tie. See Figure 4.2.
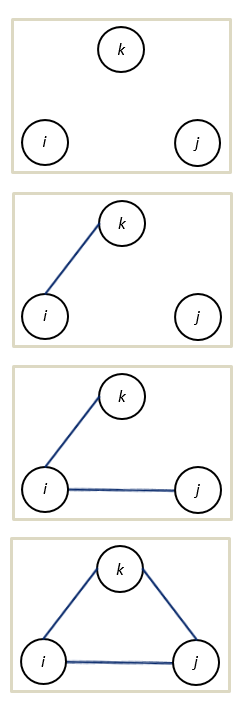
Figure 4.2: undirected triad configurations
We observe an unconnected triad, a triad with a connected pair, an open triad and a closed triad. The open triad is also called a ‘forbidden triad’ and actor i in such a triad is said to hold a ‘brokerage position’.
How many isomorphs can you think of for a triad with one connected pair?
We only have three nodes but network structures become complex quite quickly. See Figure 4.3 for the many possible configurations for triads when we consider two different type of undirected ties (i.e. multiplexity).
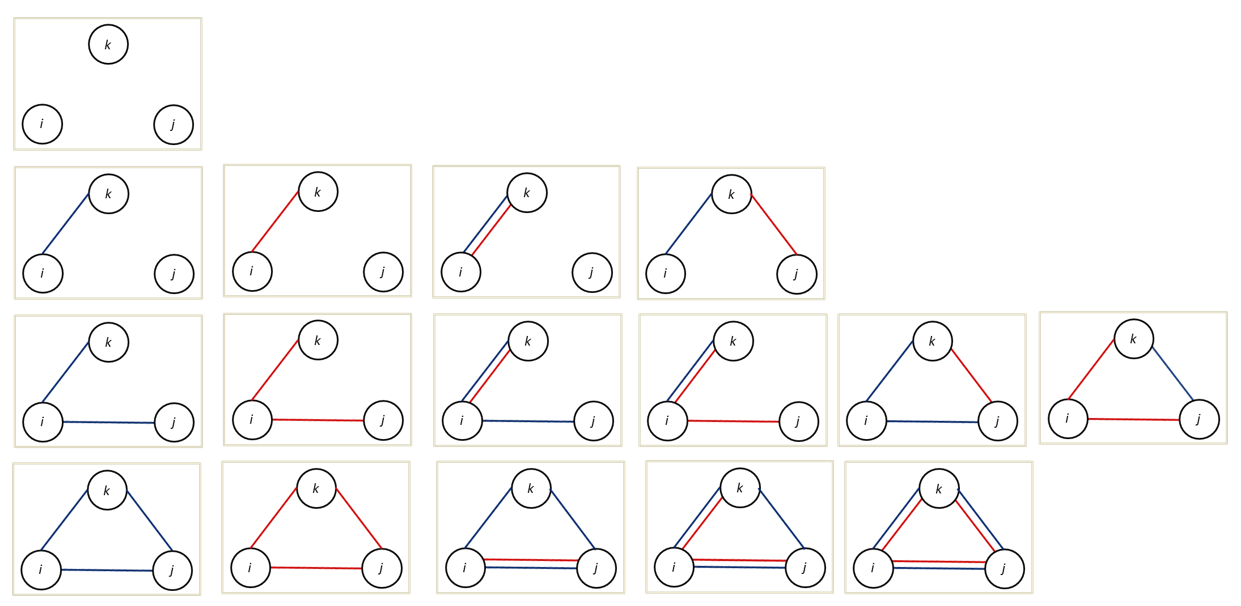
Figure 4.3: Multiplex, undirected triad configurations
And below (4.4) you will find the 16 different triad configurations for directed networks.

Figure 4.4: Directed triad configurations
These triads all have unique names:
- last digit: number of dyads without ties
- second digit: number of dyads with one tie
- first digit: number of dyads with two ties (mutual dyads)
- specific subtype:
- C: cyclic
- D: downward
- U: upward
- T: transitive
This triad census has been developed by Davis and Leinhardt (1967) and their original picture in the paper is too cool not to show here:
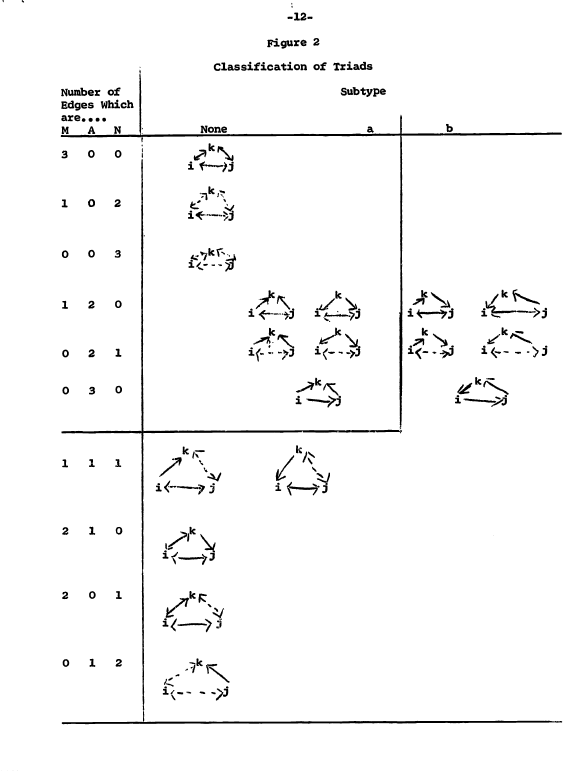
Figure 4.5: Original Triad census by Davis and Leinhard (1967)
Suppose we are trying to come up with an explanation for why we observe transitive triads (030T) in our network. We must realize that a transitive dyad may be the outcome of different evolution processes. See Figure 4.6.
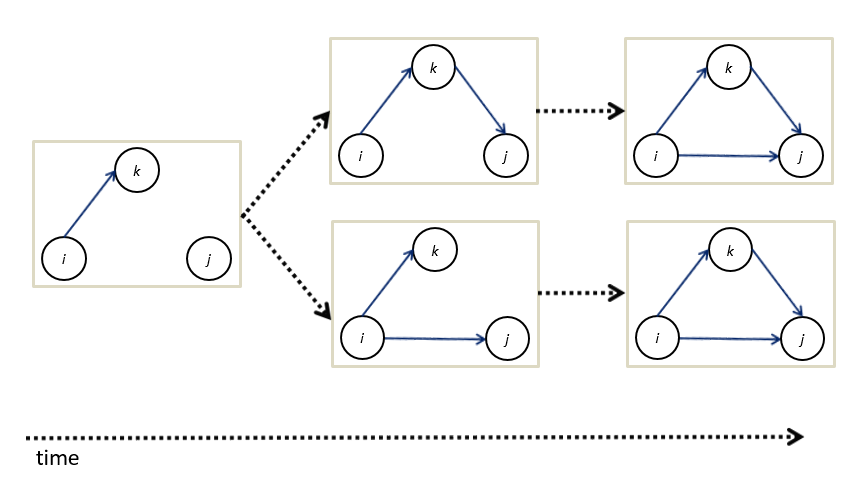
Figure 4.6: Different pathways to a transitive triad.
That is, if we assume that each tie is made subsequently, thus not two tie are created at the same time.7 The reason why i closes the triad, may be very different from the reason why k closes the triad. It all depends on the social relation under consideration. The take home message is that we need longitudinal data if we would like to disentangle specific explanations.
See Figure 4.6. Do you think both pathways are just as likely for (a) ‘friendship relations’, (b) ‘who kicks whom relations’ and (c) ‘who explains social network analysis to whom? relations’?
I could not find a nice picture of all possible directed triad configurations for two relations simultaneously. If you have time on your hands, please make one for me! 😀
So, let us go back to egonets.
4.2 Type of explanations
If social scientists seek explanations for why we observe specific social networks the explanations generally refer to four aspects, or ‘theoretical dimensions’, of social networks, namely:
- size: the number of nodes in the network
- structure: the relations in the network
- composition: characteristics of the nodes in the network
- evolution: change in size, structure and/or composition
- network growth
- tie evolution: structure –> structure
- node evolution: node attributes –> node attributes
- influence: structure –> node attributes
- selection: node attributes –> structure
Where 1, 2 and 3 belong to the causes of social networks, evolution processes belong the the consequences of social networks.
4.3 Causes
4.3.1 Size
A dyad is by definition constituted by just two nodes. The size of an egonet may vary.
In section 1.4.1 we introduced the egonet formed by our ‘Best Friend Forevers’ (BFF). Naturally, we don’t have many BFFs. Perhaps it is even a bad example because don’t you have at most only one BFF by definition? That said, my daughter (6 years old) claims that all her classmates are BFFs. Anyways. It turns out that if we ask a random sample of adults the following question…
From time to time, most people discuss important matters with other people. Looking back over the last six months—who are the people with whom you discussed matters important to you?
…that there are not many people naming more than five persons.8 For example, have a look at the table below. Data is from a dataset called CrimeNL (Tolsma et al. 2015).
| Zero | One | Two | Three | Four | Five | Mean | SD | |
|---|---|---|---|---|---|---|---|---|
| All confidants | 17.71 | 31.48 | 23.71 | 14.45 | 6.65 | 6.00 | 1.79 | 1.39 |
| Higher educated confidants | 39.91 | 31.53 | 15.26 | 7.69 | 3.50 | 2.11 | 1.10 | 1.23 |
Source: CrimeNL
N=3.834 (own calculations)
The network of our so-called confidants is called the Core-Discussion-Network (CDN).
Our CDN network thus commonly consists of maximum 5 confidants. The same holds true if we would ask about our loved ones.
4.3.1.1 Dunbar’s number
How would we get to know people with whom you form meaningful relations. That is, the people with whom you form stable social relations with and of whom you know how everyone is connected to one another. Perhaps we could use the following question:
Who would you not feel embarrassed about joining uninvited for a drink if you happened to bump into them in a bar?
My answer would definitely depend on whether it was asked to me before or after corona. 😉
Let try a different question:
Who do you send a Christmas card?
Mind you, this question to tap into your meaningful relations was constructed before e-cards existed.
According to Robin Dunbar most people are able to maintain stable social relations with approximately 100-200 people, with 150 being a typical number and it is hence known as Dunbar’s number (Dunbar 2010; Dunbar et al. 2015).
According to Dunbar each layer of our social network has a typical size, where the size of each layer increasing as emotional closeness decreases:
- loved ones: 5
- good friends: 15
- friends: 50
- meaningful contacts: 150
- acquaintances: 500
- people you can recognize: 1500
4.3.1.2 online ‘friends’
Many people are active on online social networks like FaceBook, Instagram, Strava or what have you. According to this site, approximately 40% of U.S Facebook users in the United States (in 2016) had between 0-200 friends, 38% 200-500 friends and 21% 500+ friends.
There are several crucial differences between the connections we have online versus offline. First of all, it does not cost many resources to make and maintain an online friendship. It may require some social media skills though, which I found out the hard way. After having joined FB at a time when youngster were already moving on to other online communities, it annoyed me to see all kind of uninteresting stories of distant relatives about their cats. I consequently decided to unfriend these persons. This was not appreciated by some other relatives. It turned out I should simply have hidden their content from my timeline. There apparently is a social norm not to unfriend people on FB.
We already discussed that selection processes should be seen as distinct from deselection processes. I would argue that especially with respect to online social relations within the selection part we need to distinguish processes explaining sending friendship invitations and accepting/declining friendship invitations.
But notwithstanding these differences, online social networks consist of a series of embedded layers just as offline personal social networks.
4.3.2 Structure
In this section we will discuss several network measures. In this chapter we focus on egonets but many measures are also relevant for complete networks!
To illustrate some different ways how we could describe egonets we will use egonets based on co-authorships. We start with randomly sampling two social scientists from the total pool of all social scientists. Currently rolling a dice…and who did we sample…:
- Bas Hofstra
- Jochem Tolsma
From these two sampled social scientists we will use the webscraping techniques described in Chapter 8 to collect 1.5 degree co-author egonetwork.
See the figures 4.7 and 4.8 below for a quick-and-dirty graphical summary of the networks.
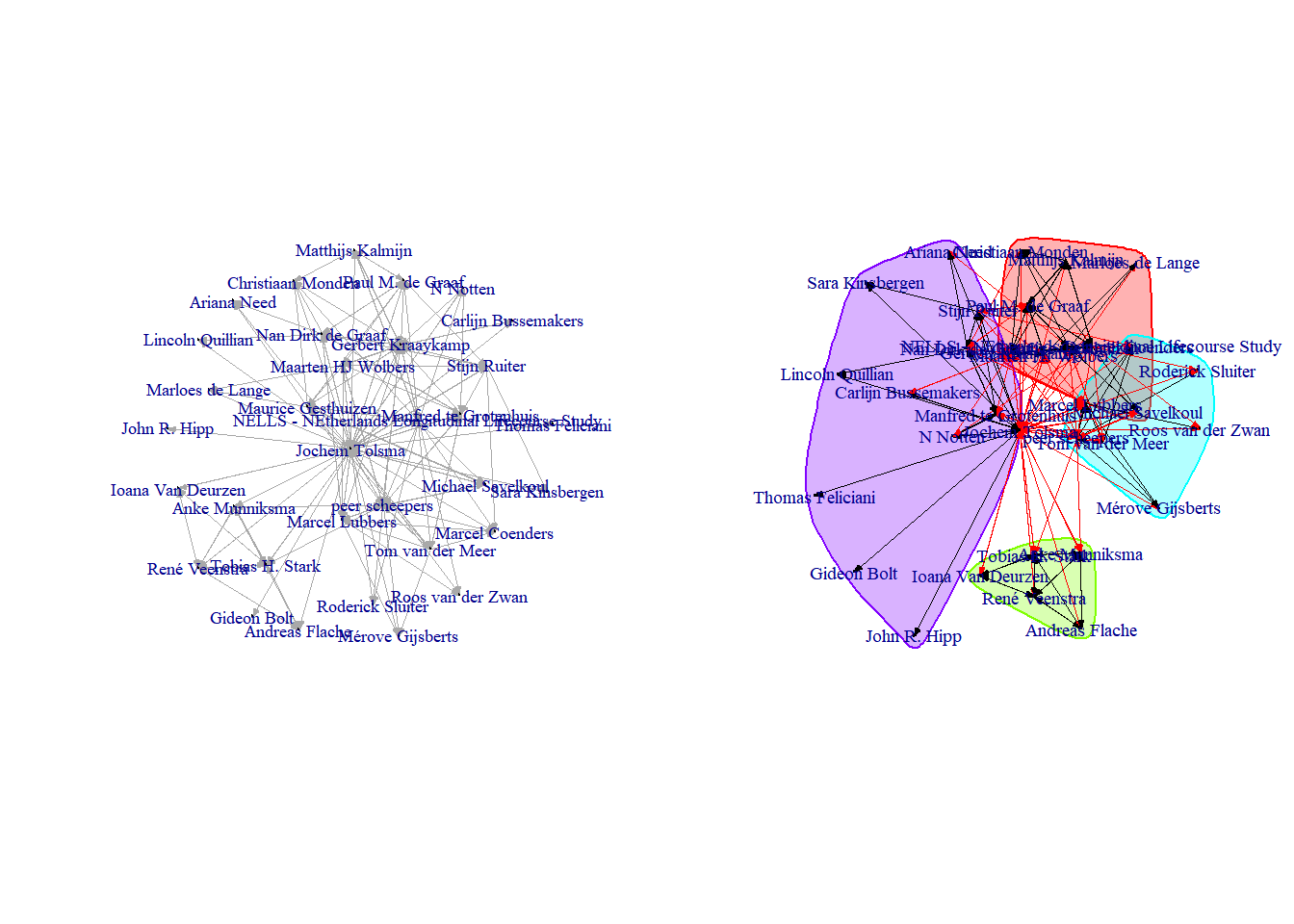
Figure 4.7: 1.5 degree co-author egonetwork of JOCHEM TOLSMA
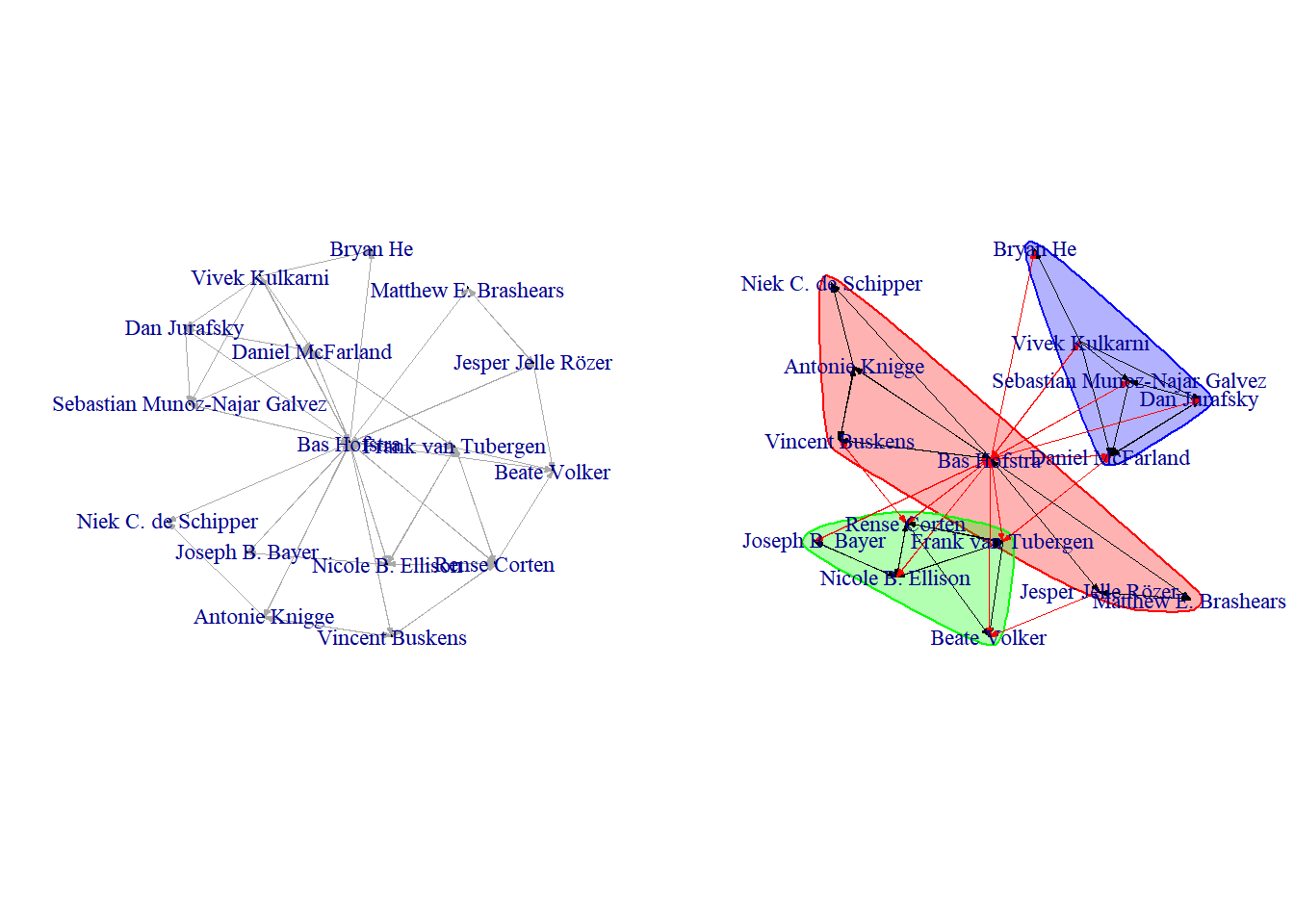
Figure 4.8: 1.5 degree co-author egonetwork of BAS HOFSTRA
4.3.2.1 Density
Density is defined as all observed relations divided by all possible relations. Look at the examples below. Are you able to calculate the density of the networks yourself?
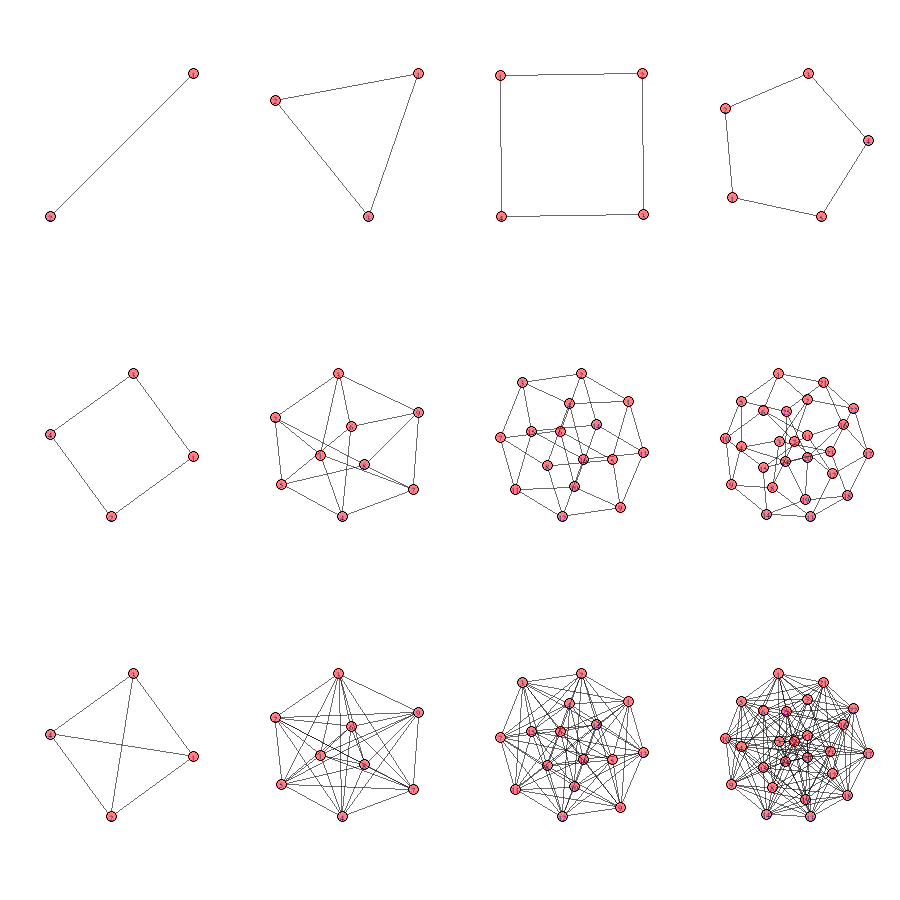
Figure 4.9: Different densities?
The density in Bas’ network turns out to be: 0.22.
The density in Jochem’s network turns out to be: 0.15.
For comparison, if we look at friendship networks among pupils in classrooms, we generally observe a density within the range of .2 and .4.
4.3.2.2 Degree centrality
Closely related to density is the concept of degree. The number of ingoing (indegree), outgoing (outdegree) or undirected (degree) relations from each node. In real social networks, we generally observe a right-skewed degree distribution (most people have some friends, few people have many friends).
Centrality measures, like degree, can be measured at the node-level. For the graph as a whole, we may calculate the average centrality score but every node-level centrality measure also has its specific graph-level analogue. In what follows we focus on node-level centrality scores.
At the node-level we may calculate the raw measure but to facilitate interpretation we will use normalized measures. There may be more than one way by which the raw scores can be normalized. If you use an R package to calculate normalized centrality scores (e.g.igraph), please be aware of the applied normalization.
People in a network with relatively many degree are called more central and (normalized) degree centrality is formally defined as:
\[ C_D(v_i) = \frac{deg(v_i) - min(deg(v))} {max(deg(v)) - min(deg(v))}, \]
where \(C_D(v_i)\) is degree centrality of \(v_i\), vertex i, and ‘deg’ stands for ‘degree’. \(max(deg(v))\) is the maximal observed degree. \(min(deg(v))\) is the minimal observed degree. A different normalization approach would be to divide the node degree by the maximum degree (either the theoretical maximum, or the maximal observed degree).
Suppose you want to compare the degree centrality of all co-authors in Bas’ network. Which normalization approach would you take?
Suppose you want to compare the degree centrality of Bas in Bas’s network with the degree centrality of Jochem in Jochem’s network. Which normalization approach would you take.
4.3.2.3 Closeness centrality
Closely related to degree centrality is (normalized) ‘closeness centrality’:
\[ C_C(v_i) = \frac{N}{\sum_{j}d(v_j, v_i)}, \]
with N the number of nodes and d stands for distance.
4.3.2.4 Betweenness centrality
A final important measure of centrality I would like to discuss is called betweenness. It is defined as:
\[ C_B(v_i) = \sum_{j\neq k\neq i} \frac{\sigma_{v_j,v_k}(v_i)}{\sigma(v_j,v_k)}, \]
where \(\sigma(v_j,v_k)\) is the number of shortest paths between vertices j and k, \(\sigma_{v_j,v_k}(v_i)\), are the number of these shortest paths that pass through vertex \(v_i\) . One way to normalize this measure is as follows:
\[ C_{B_{normalized}}(v_i) = \frac{C_B(v_i) - min(C_B(v))}{max(C_B(v))-min(C_B(v))} \]
4.3.2.5 Clustering
Clustering is an interesting concept. We have immediately an intuitive understanding of it, people lump together in separate groups. But how should we go about defining it more formally? The clustering coefficient for \(v_i\) is defined as the observed ties between all direct neighbors of \(v_i\) divided by all possible ties between all direct neighbors of \(v_i\). Direct neighbours are connected to \(v_i\) via an ingoing and/or outgoing relation. Let \(k_i\) be the number of neighbors of \(v_i\) and let \(\sum{e_{jk}}\) be the number of edges between these neighbours, then we can define the local clustering coefficient as:
\[ C_C(v_i) = \frac{\sum{e_{jk}}} {k_i * (k_i -1)} \]
For undirected networks, the clustering coefficient is the same as the transitivity index: the number of transitive triads divided by all possible transitive triads. For directed graphs not so.
Bas’ transitivity network in his network turns out to be: 0.18.
Jochem’s transitivity in his network turns out to be: 0.15.
4.4 Consequences
Please brush off your knowledge on dyadic influence processes (see section 2.3.2). What is the added complexity of egonets? Phrased otherwise, why would some egonets exert more influence than other egonets?
- The size of egonets may differ (i.e. node set).
- The structure of egonets may differ (i.e. tie set).
- The composition of egonetes may differ (i.e. attribute set).
- The evolution (stability) of egonets may differ.
Surprisingly, there is relatively little literature on influence processes going on in egonets. The literature is mainly concerned with dyadic influence process or on influence processes going on in socionets. We also need to be aware that the debate on the consequences of egonets is dominated by researchers interest in the topic of social capital.
My definition of social capital is…:
Social capital is the extent to which our egocentric networks gives us access to different forms of ‘capital’ or resources which we may use to our own benefit.
Please compare my definition with Nan Lin’s definition:
The resources embedded in a social structure that are accessed and/or mobilized in purposive actions. (Lin 2002).
Social capital is one of the most heavily disputed concepts in the social sciences. For more definitions see socialcapitalresearch.com.
The literature on how egonets may influence our opinions and attitudes is sparse. We will discuss egonet influence processes during class and I will upload a lecture with my take on this asap.
TO DO: upload lecture
4.5 Assignment
Please prepare a short (5-10 min.) presentation on recent developments in the literature that deals with causes for egonets. More specifically pick one topic:
- egonets and size (i.e. node set). Start with Paik and Sanchagrin (2013).
- egonets and structure (i.e. tie set). Start with Adamic and Adar (2003).
- egonets and composition (i.e. attribute set) Start with Hofstra et al. (2017).
- egonets and evolution / stability. Start with Small, Pamphile, and McMahan (2015).